 Mind Foundry
Mind Foundry
The Intelligent Application of Machine Learning in Defence
The rapid and dislocating advances in large language models (LLMs) and foundation models over the past three years has dominated the AI and machine...
Last year, Mind Foundry worked closely with Professor Brent Mittelstadt (of the Oxford Internet Institute) to get a deeper understanding of the law, policy, and standards in development surrounding machine learning. The output of this work was an in-depth research paper highlighting the key aspects of machine learning governance. This 4-part blog series summarises some of the key points from that paper to give a flavour of the most pressing problems in AI governance and some of the solutions that Mind Foundry are developing to solve them.
Professor Brent Mittelstadt of the Oxford Internet Institute is the author of highly cited works across the topics of fairness, accountability, and transparency in machine learning and the auditing of automated systems.
Part One: What makes a machine learning model trustworthy?
Global interest in artificial intelligence (AI), machine learning (ML), and algorithmic decision-making has grown enormously and rapidly in the past decade. Amidst the excitement around the possible benefits of these technologies, considerable interest has simultaneously grown around their impacts and risks for society. Machine learning model malfunction or failure can have catastrophic consequences, especially in the context of high-stakes applications.
So, what does it mean for a model to be ‘trustworthy’? How can we deploy a model with confidence that it will perform as intended? Or at least that the necessary escalation will occur to fix the issue?
Taking a broad view, outside of machine learning, going to the core elements of trustworthiness, University of Oxford trust expert Rachel Botsman highlights how within human interpersonal relationships, there are two axes which influence how trustworthy we deem a person: (1) in ‘how’ individuals do things: competence and reliability; and (2) in ‘why’ individuals do things: integrity and empathy. Despite these traits being used to describe trustworthiness within individuals, these facets apply to how we might deem AI models and AI agents trustworthy.
How do models do things?
These facets of trustworthiness have clear applicability in the context of machine learning:
Competence: It must be made clear where this model has been trained to succeed or where it may have serious limitations in its capability. The model should be sufficiently tested to ensure it can perform in its designated production environment. Interpretability methods can also help to demonstrate how the model is influenced.
Reliability: It is important to ensure that the model will consistently behave in the way it was intended over time. As changes in data inputs can cause the model to malfunction or fail in production, users should have observability of the performance and data drift of the model.
Why do models do things?
While integrity and empathy are typically two human traits, as well as the broader question of ‘why’ we do things, being associated with humans, it is important to be cognisant of the human labour that is required for machine learning models to perform their functions. As Microsoft researcher Kate Crawford highlights in her latest book, much human labour and intelligence go into creating machine learning models, from the data collection, data labelling, feature engineering, serving of the model, and thresholds for sensitivity in maintenance. As such, machine intelligence is inextricably linked to human intelligence. Consequently, these traits also encapsulate some key elements around the building of machine learning:
Integrity: Ensuring datasets are representative of the world and proportionate to the problem being solved. Understanding how labels were sourced can help to reveal any errors or skew. Was this model created in a scientifically rigorous way? Does the model suffer from overfitting?
Empathy: While the onus will be on the human creators of the machine learning system, this trait calls into question the appropriateness of machine learning for a specific use case. The focus is a normative question: should machine learning be used to solve a particular problem? And, if so, is there a way for citizens or other non-users to contest an inference a machine-learning model has made about them?
These human dimensions of trustworthiness can help frame how we might think about trust in the context of machine learning. Critical to the issue of the trustworthiness of machine learning is the idea that systems are justifiably trusted; they are not erroneously gaining users’ trust.
So, now we have talked about the kinds of facets that may enable us to think about ‘trustworthiness’; what are the specific machine learning axes that can help us to measure how confident we should be in a machine learning system?
We will be highlighting some of the most commonly cited areas for machine learning trustworthiness:
Bias and fairness
Interpretability
Data drift and model fragility
What are the main axes of model trustworthiness?
1. Bias and Fairness
Within mainstream media, bias and fairness within AI and algorithmic decision-making are commonly raised and discussed. There have been multiple scandals which make this risk evident. A key challenge within this space is to choose methods and metrics that can consistently detect subtle biases inherited by models and from training inputs. This is a non-trivial task, as bias and resulting unfair outcome distributions have many causes, including historically biased distributions, selection bias (non-representative training data), and prediction bias (predictions based on protected attributes or proxies).
For example, the choice of features may create unwanted bias. Consider the example where a machine learning model’s target is to help a bank decide whether to give an individual a loan. One feature might be the ‘number of previous loan application rejections’. While such a feature may seem ‘objective’ or benign, it is possible this value may have been influenced by historically biased distributions; if such a feature has importance in the model, it may contribute to a self-fulfilling prophecy.
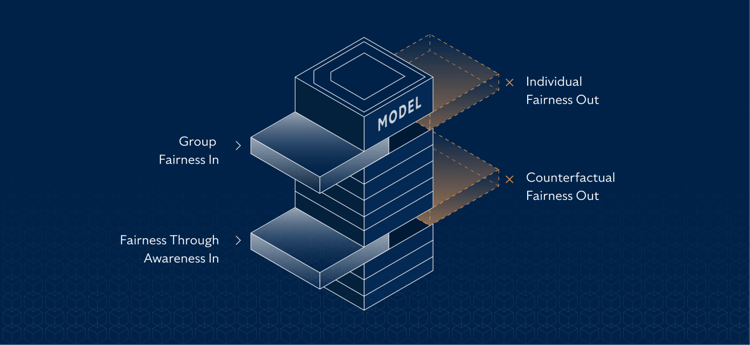
There are numerous ways to approach fairness, with multiple definitions that can be applied to create countless differences in the model outcome. Broadly, the metrics can be categorised into four main groups:
Group fairness (parity between different protected groups such as gender or race)
Individual fairness (similar individuals treated similarly)
Fairness through awareness (individuals who are similar with respect to a particular task should be classified similarly)
Counterfactual fairness (outcomes are the same in the actual world and a ‘counterfactual world’ where an individual belongs to a different demographic group).
The challenge is that one fairness metric may necessarily preclude another choice of metric. This is the case in (1) group fairness vs individual fairness and (2) counterfactual fairness vs fairness through awareness; they are inherently opposing views of fairness. Another difficulty in using fairness metrics is that they produce inaccurate results when actual differences exist between groups in a target variable or prediction.
While bias and fairness considerations are clearly important, this is just one of the many facets of machine learning trustworthiness.
2. Interpretability and Explainability
Intuitively, some aspects of explainability might be important to satisfy ‘fairness’ and bias considerations. For example, in 2019, Goldman Sachs’ credit card policies were called into question for gender discrimination, with individuals citing that female partners received lower Apple Card credit limits than their male spouses. Under investigation, Goldman Sachs demonstrated that gender was not a characteristic used to determine credit limits; rather, credit utilisation, unpaid debt, and credit history were key features. Interpretability played a key role in clearing Goldman Sachs for gender discrimination charges. Whether or not these are still ‘proxy features’ given possible historically biased circumstances, and if the outcome can be said to constitute ‘fairness’, is a different discussion. Crucially, though, interpretability is effective for demonstrating how a model works and may challenge our a priori assumptions about a model’s outputs.
Now that we know how explainability might relate to fairness and bias considerations for a model in production, let’s look at what both interpretability and explainability refer to. Interpretability refers to the degree to which a model and its behaviours are understandable to an external observer. Interpretability methods address the (1) internal functionality or (2) external behaviour of a model. To achieve full internal functionality, models must have the entire causal chain (from input data to outputs) understood by an observer. In practice, fully interpretable models are rare. However, there is a range of methods which can provide varying levels of interpretability in models. This includes –
Outcome explanation methods, e.g. creating a locally interpretable approximation model that can explain the prediction of the black box in an understandable term for humans.
Model inspection methods that can explain the black box model or its prediction.
Transparency box design methods that are considered ‘interpretable by design’, e.g. models where you can see feature importances.
Generally, there is a considerable difference between ‘post-hoc’ interpretation methods, i.e. methods which try to explain opaque models and interpretable by design methods. It is assumed that the latter provides better, more consistent results.
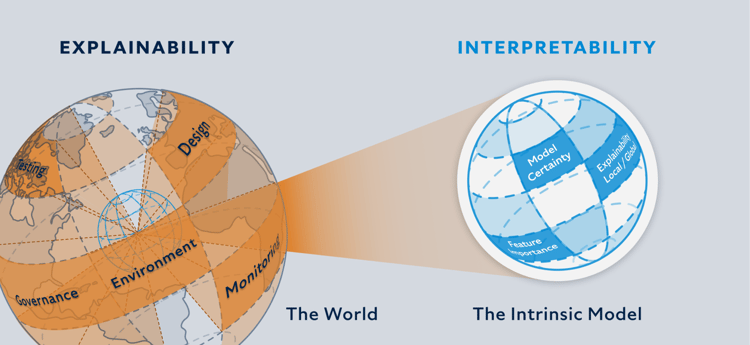
It is important to distinguish between interpretability and explainability. Interpretability refers to the technical methods to actually peer under the model's hood and provide information such that human beings could, at the parametric level, understand how the model came to the outcome. Explainability tends to refer to the human understanding of how the model works. This focuses on grasping the concept at an intuitive level. Interpretability is a prerequisite for explainability, but interpretability may not necessarily yield an explanation deemed sufficient.
Machine learning monitoring: Data Drift
Fairness & bias and interpretability & explainability are all key parts of making sure both data inputs and prediction outcomes can be trustworthy. Another important aspect is to monitor how your model, once deployed, is serving predictions. One of the key things to monitor is data drift.
What is data drift?
Drift refers to some kind of mismatch between the coverage of the training dataset and the production environment, which results in a degraded model performance or other errors/failures. Broadly, data drift encapsulates a change in the distribution of data used in a predictive task. In order to ensure a model continues to be trustworthy once it is deployed, it is important to measure drift in your model as it gets retrained and updated with new data. This can prevent the model from underperforming or catastrophically failing. Below, we can see how different changes in data input can cause different issues for models. There are different kinds of data drift:
Covariate shift: previously infrequent or even unseen features become more frequent. The relationship between the features and the target remains the same. Consider an AI speech recognition tool that can automatically transcribe speech to text. The model might be trained using data from speakers only from a specific area of England. The model will perform well on this training data. However, it will not perform as successfully when processing speech from speakers with different accents.
Prior probability shift: the distribution of the target variable gets modified, for example, changing the proportion of samples belonging to one class into another. Consider a training set that has prior probabilities on spam emails. The training set has a prior probability of spam emails being 50% spam and 50% non-spam. If, in reality, 75% of emails are non-spam, this prior probability may wrongly influence the model’s output distribution.
Concept shift: the dependence of the target on the features evolves over time. This is when the entire way we might categorise a behaviour or ‘class’ changes. For example, a concept shift might occur if what constitutes ‘fraudulent behaviour’ today became more difficult to detect in future due to those committing fraud evolving their tactics over time. This can happen if what was once deemed fraudulent is no longer fraudulent due to some world event or change in policy.

We’ll be taking a deeper dive into data drift and how to monitor this in a live machine-learning model in the next release of our 4-part blog series on ML governance in responsible AI.
To conclude, there are many methods for ensuring that machine learning models are more trustworthy, but three areas of particular focus are (1) bias and fairness, (2) interpretability and explainability, and (3) monitoring models for data drift. While this is a non-exhaustive list of model trustworthiness, these components form an essential part of how we might trust a machine learning model. The more model management systems enable observability into these key areas to the users of the predictions, the more teams and organisations can be empowered to use AI responsibly over time. When decisions have a material impact on the lives of individuals and populations, the importance of model trustworthiness and responsibility cannot be overstated.
About the Authors
Brent Mittelstadt
Professor Brent Mittelstadt is the Oxford Internet Institute’s (University of Oxford) Director of Research, an Associate Professor and Senior Research Fellow. He is a leading data ethicist and philosopher specialising in AI ethics, professional ethics, and technology law and policy.
He has contributed several key policy analyses, technical fixes, and ethical frameworks to address the most pressing risks of emerging data-intensive technologies, including legal analysis of the enforceability of a “right to explanation” of automated decisions in the General Data Protection Regulation (GDPR).
Professor Mittelstadt worked with Mind Foundry to evaluate the latest AI policy developments and state of the art in AI governance, which has informed Mind Foundry’s development of machine learning governance capabilities.

The rapid and dislocating advances in large language models (LLMs) and foundation models over the past three years has dominated the AI and machine...

From detecting hidden threats to defending critical underwater infrastructure, Anti-Submarine Warfare (ASW) is a cornerstone of national security. AI...

The UK-USA Technology Prosperity Deal sees overseas organisations pledging £31 billion of investment into UK AI infrastructure. As AI investment...