 Mind Foundry
Mind Foundry

The Intelligent Application of Machine Learning in Defence
The rapid and dislocating advances in large language models (LLMs) and foundation models over the past three years has dominated the AI and machine...

There’s been a lot of talk about the development of large language models (LLMs) recently, with the loudest voices split between those who think it poses a significant risk to humanity and those who believe it could be the crowning achievement of all humankind. Between those two extremes are numerous reasons for optimism and many valid concerns about AI safety and how to use LLMs responsibly across many different sectors. Much of this hinges on ‘transparency’, ‘interpretability’, and ‘explainability’.
We interviewed Professor Steve Roberts, Co-founder at Mind Foundry and Professor at the University of Oxford, and invited him to share with us how he explains the meanings of these three terms to his students.
Setting the Scene - LLM, Black Boxes, and Transparency
One of the challenges with LLMs is that they are often seen as 'black boxes', meaning that it can be difficult for researchers and users to understand how the models make their decisions or generate their outputs. This lack of transparency is problematic, especially in high-stakes applications where it is important to explain the reasoning behind an AI system's decisions, such as in legal or ethical contexts or when a decision affects the lives of millions of people. Transparency must be the starting point for any AI solution deployed in the workplace to ensure it is implemented responsibly and by people and organisations that understand its capabilities, limitations, and consequences.
Achieving transparency in AI is an important field of study in AI research. Still, it’s one that can confuse many people who may not understand the differences between words like ‘transparency’, ‘explainability’, and ‘interpretability’. To some, they’re synonyms that mean something about how much we can understand the inner workings of an AI. To others, especially those actively working in Machine Learning (ML), they have much more nuanced meanings. And though no diverse group of experts are likely to completely agree on the actual definitions, we can make some safe observations about the deeper meaning of these words, which can, in turn, help us understand AI and its impact on our lives in a more profound way.
An Interview with Professor Roberts
Q: At a high level, how do you explain ‘transparency’, ‘interpretability’, and ‘explainability’ to your students?
Professor Roberts: I love this question, and it often comes up. And when it does, I like to explain it with what I call the 'AI Triangle', which has the model, the data, and the inference at its vertices.
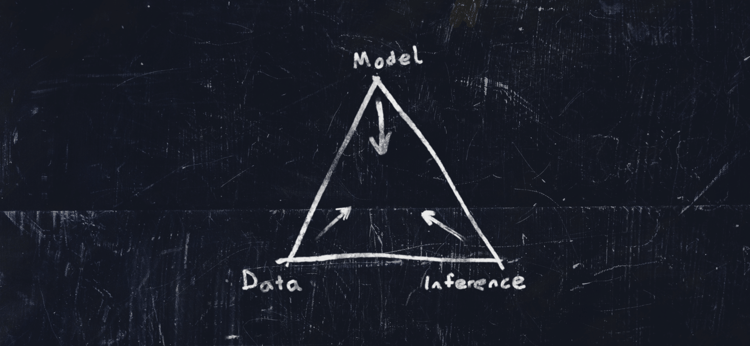
These three concepts all have to come together in order to work in a deployed solution. If you take away one of them, it breaks. So, when we talk about transparency, we mean transparency across the entire space of the AI triangle.
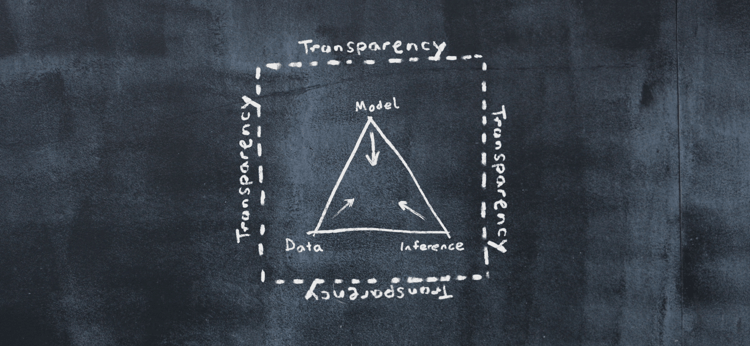
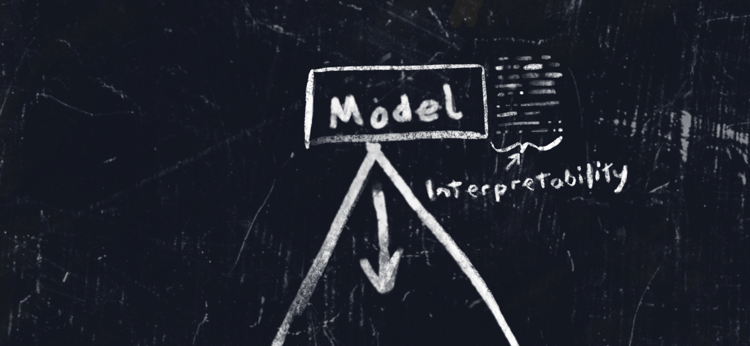
Q: Where does interpretability come in?
Professor Roberts: Often, interpretability has more to do with the model. This is more technical. An interpretable model is one that openly shows its internal workings and provides information so that we as human beings can drill down and understand, at least at a kind of parametric level, how the model came to a particular solution.
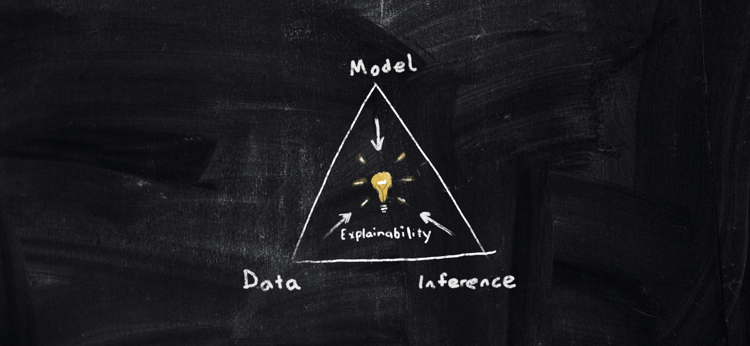
Q: Where would you put explainability?
Professor Roberts: Explainability tends to deal with human understanding. Each human is different and has a different capacity for understanding, so this one is more of a broad brush.
For example, let's say we’ve built a model that has something to do with kinematics (a branch of classical mechanics that deals with the motion of objects). The interpretability aspect of the model might explain, through rules, data, huge decision trees, and all of the other things that go into the model's inner workings, to help explain a ball falling under gravity. The interpretability lets us peer under the hood to see how every part is moving.
But the explainability of this model would be the ‘aha’ moment that comes when the real meaning of something is grasped at an intuitive level. It’s being able to transfer all that data into something which you can almost feel in your stomach as you get your head around it all and eventually end on an insight like “Oh, of course… Because of the conservation of energy. That makes sense!”
Q: In today’s world, are most models explainable?
Professor Roberts: No, most are not. Instead of gut feelings of explainability, most models, if they are interpretable at all, require you to sort of bend your consciousness to become the mind of a machine in order to understand what all the weights on a neural network really mean. And that’s not easy for most humans to do. I certainly struggle with it.
Q: Is explainability really about understanding?
Professor Roberts: Yes, that’s right. It's about knowing at a deep level rather than drowning in the pedantry of detail. It's not seeing a thousand values that describe the ball as it moves, as it's being dropped to the ground. It's about the fundamental ‘aha’ moment when you realise that all that complexity can be explained by a really simple concept.
As far as the state of the industry today, explainability is more about attaining conceptual understanding, and that really goes beyond the majority of what most AI models are capable of right now.
It’s important to remember that definitions are still semantic and will continue to evolve and change as the meanings of words always do. And though they can be interpreted in different ways, and experts will come up with their own definitions, we’ve found these to be particularly useful; they help us to demarcate where we are when we’re talking about our ability to interpret, explain, and ultimately understand not just the three components of the AI triangle, but also the way AI interacts responsibly with and forms a part of systems and systems of systems in the real world.
Enjoyed this blog? Check out "Generative AI: The Illusion of a Shortcut"

The rapid and dislocating advances in large language models (LLMs) and foundation models over the past three years has dominated the AI and machine...

From detecting hidden threats to defending critical underwater infrastructure, Anti-Submarine Warfare (ASW) is a cornerstone of national security. AI...

The UK-USA Technology Prosperity Deal sees overseas organisations pledging £31 billion of investment into UK AI infrastructure. As AI investment...