 Mind Foundry
Mind Foundry
The Intelligent Application of Machine Learning in Defence
The rapid and dislocating advances in large language models (LLMs) and foundation models over the past three years has dominated the AI and machine...

As AI capabilities advance, and with the advent of widely available low-cost cloud computing, AI will inevitably be applied to wider problem sets with more immediate and wide-ranging real-world impacts, bringing with it higher problem complexity and increased risk. As problem complexity and risks grow, the assurance of AI performance data cleanliness naturally transitions from pre-deployment considerations, instead becoming continuously evolving requirements which must be monitored and iterated on throughout a model’s life.
This continuous monitoring and improvement cycle present an opportunity for human experts to continue to impart knowledge and understanding in challenging areas of the problem space as they’re identified during operations. This approach can be even more performant when models are explicitly designed with active learning to search out areas for expert human feedback where performance is less robust and a small human input can drive large model performance improvements.

Training models with less data
In many cases, it’s possible to achieve good performance in a model without using large datasets. A large number of data points in most datasets encode repeated information with literal relative value to the dataset as a whole. This results in increased training costs for comparatively small returns in performance gain.
As AI is deployed on more complex and high-stakes problems, it becomes prohibitive to build datasets which encapsulate the entire problem space at training time; we simply can’t characterise the entire space without extensive hands-on use and experience, which will surface new, in-operation requirements. Instead, training must be considered as an ongoing process with architectures designed to capture the changing nature of AI problems, identify improvements together with human oversight, and continue to improve their capability over time.
Actively seeking out areas of uncertainty and opportunities to gather human feedback and more information can ensure that the model function becomes more robust and reliable over time and minimises the risk of failure or mistakes resulting from evolving problem characteristics. Equally, such an approach reduces the unrealistic burden on human experts to download and encode their entire expertise to a model at the point of training, instead enabling them gradually to impart advice in contextually relevant scenarios encountered during operational use.
Removing the upfront burden of training models to perfection also allows AI models to be deployed and start delivering value with less data, time and training investment. Assurance can instead become an ongoing concern rather than a discrete step. Model performance can then improve on the fly through oversight and involvement of human experts in a hybrid, human-AI collaborative system.

Operational Considerations
Very few AI applications are static; data and problem characteristics will change over time. It’s dangerous, therefore, to allow the deployment and use of models without careful monitoring and requisite updates in response to these changes. Many AI applications resort to frequent human-driven benchmarking and performance assessments to detect and resolve data drifts and model degradation, but this can be expensive, leading to future “process optimisations” which remove these vital activities. Continuous monitoring and targeted active learning provide a smoother alternative. By including the facility for algorithms to query human experts on areas of uncertainty or for validation, it is possible to continually monitor and improve performance, removing the need for resource-intensive batch assessments and updates. This results in models that remain more up-to-date, a workforce that is better engaged with the problem, and more smooth, predictable resource requirements for continued maintenance.
For some problems, it may not only be acceptable to train models to a percentage maximum performance, but it may also result in significant savings in cost and emissions resulting from computing. Model accuracy is just one facet of performance when we consider operationalised AI, with value cost tradeoffs and environmental impact also important to consider. However, in high-stakes problems, the difference between 95% and 99% accuracy can result in lives saved or lost, so it’s important that accuracy and reliability are maximised. Continuous learning architectures mean that this doesn't need to be a binary decision; areas of improvement can be identified through operational experience rather than speculatively catered to at training time. This enables intentional and efficient use of compute power in important areas of the problem space rather than more expensive, less targeted performance improvements pre-deployment.
By considering AI not as a product to be handed over but as a service which grows and improves over time in response to the changing nature of the world, it’s possible to build systems with far greater performance, which can function in the most challenging applications, without prohibitively large dataset and training compute requirements.
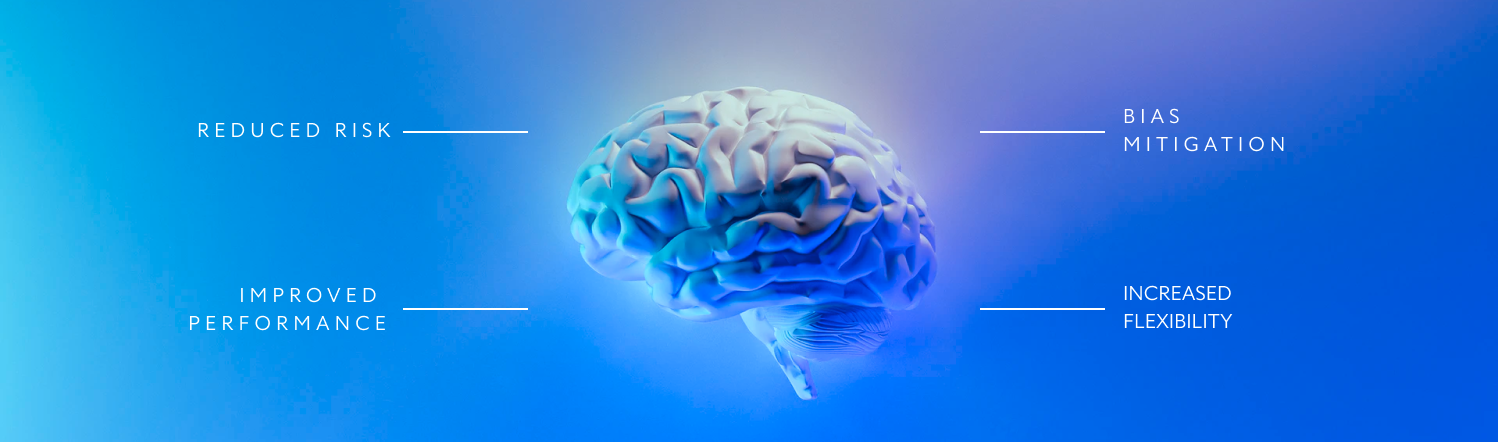
A solution to production challenges
Mind Foundry’s technology leverages active learning capabilities through our continuous metalearning and human-AI collaboration architectures, combining the speed and scalability of digital decision-making with the contextual and situational awareness of human decision-makers. This increases model adaptability and robustness and makes the function more suited to real-world applications as models transition from lab-based research projects to meaningful contributors across the enterprise:
Reduced risk - By including humans as collaborators in the system, close to the point of decisioning, they can quickly rectify errors made by the AI, preventing issues from propagating through and impacting the wider system.
Improved performance over time through continuous metalearning - The AI system learns from human corrections and can ask better questions of human counterparts, increasing performance gains.
Bias mitigation through Human - AI collaboration - No single human is responsible for training the AI system. Instead, a diverse group of individuals with varying experiences and beliefs each have an impact, helping to reduce the impact of individual biases and blind spots.
Increased flexibility - Active learning lets models improve over time, removing the need to throw all available data at the model at once. This reduces training time and cost whilst enabling solution iteration as requirements change rather than requiring complete retraining.
Enjoyed this piece? Check out our article on what it means for a machine learning model to be "trustworthy"

The rapid and dislocating advances in large language models (LLMs) and foundation models over the past three years has dominated the AI and machine...

From detecting hidden threats to defending critical underwater infrastructure, Anti-Submarine Warfare (ASW) is a cornerstone of national security. AI...

The UK-USA Technology Prosperity Deal sees overseas organisations pledging £31 billion of investment into UK AI infrastructure. As AI investment...